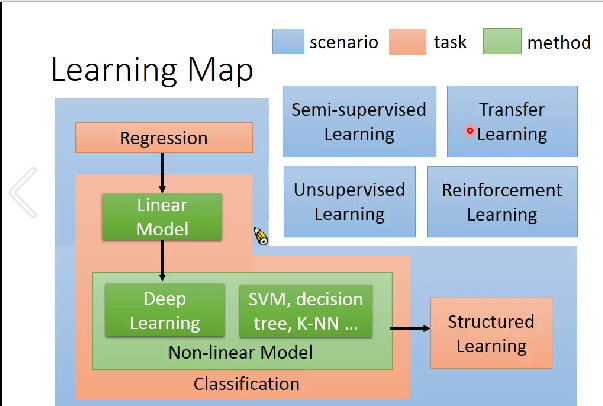
Learning Map
Regression: Case Study
y=b+w⋅xcp
(xfeature,y^)
Loss function L
input: a function output: how bad it is
L(f)=L(w,b)=n∑(y^n−(b+w⋅xfeaturen))2
Pick the "Best" Function
f∗=argfminL(f)
w∗,b∗=argw,bminL(w,b)=argw,bminn∑(y^n−(b+w⋅xfeaturen))2
Gradient Descent
- Consider loss function L(w) with two parameter w, b:
- (Randomly) Pick an initial value w0,b0
- Compute ∂w∂L∣w=w0,b=b0,∂b∂L∣w=w0,b=b0
- w1←w0−η∂w∂L∣w=w0,b1←b0−η∂w∂L∣w=w0,b=b0 η:"learning rate"
- ... Many iteration
Local optimal, not global optimal...
In linear regression, the loss function L is convex, so no local optimal
L(w,b)=n∑(y^n−(b+w⋅xfeaturen))2
∂w∂L=n∑2(y^n−(b+w⋅xfeaturen))(−xfeaturen)
∂b∂L=n∑2(y^n−(b+w⋅xfeaturen))(−1)
Regularization
L=n∑(y^n−(b+∑wixi))2+λ∑(wi)2
The functions with smaller wi are better
Training error: largerλ, considering the training error less
We prefer smooth function, but don't be too smooth
Gradient Descent
θ∗=argθminL(θ) L: loss function θ: parameters
Suppose that θ has two variables {θ1,θ2}
Randomly start at θ0=[θ10θ20]
[θ11θ21]=[θ10θ20]−η[∂L(θ10)/∂θ1 ∂L(θ20)/∂θ2]∇L(θ)=[∂L(θ1)/∂θ1 ∂L(θ2)/∂θ2]
...
θi=θi−1−η∇L(θi−1)
Watch picture

- Popular & Simple Idea: Reduce the learning rate by some factor every few epochs
- E.g. 1/t decay: ηt=η/√t+1
Adagrad
Divide the learning rate of each parameter by the root mean square of its previous derivatives
wt+1←wt−σtηtgt
ηt=√t+1ηgt=∂w∂C(θt)σt: root mean square of the previous derivatives of parameter w
w1←w0−σ0η0g0σ0=√(g0)2
w2←w1−σ1η1g1σ1=√21[(g0)2+(g1)2]
...
wt+1←wt−σtηtgtσt=⎷t+11t=0∑t(gi)2
∴wt+1←wt−√∑i=0t(gi)2ηgt
best step: Second−derivative∣First−derivative∣
Stochastic Gradient Descent
faster
Pick an example xn
Ln=(y^n−(b+∑wixin))2 Loss for only one example
θi=θi−1−η∇Ln(θi−1)
Feature Scaling
make different features have the same scaling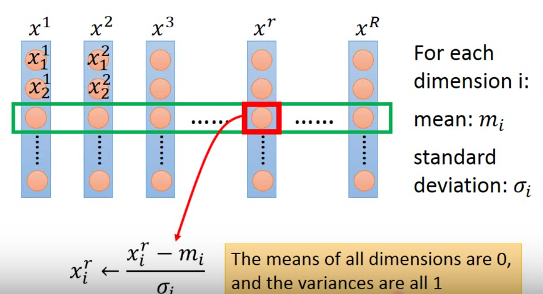
More limitation
local minima
stuck at saddle point
very slow at the plateau
Where does the error come from?
error due to "bias"
error due to "variance"
f∗ is an estimator of f^
简单model,small variance Simple model is less influenced by the sampled data.
Bias: If we average all the f∗, it is close to f^
简单model,large bias
Large bias?
Redesign your model:
- Add more features as input
- A more complex model
Large variance
Cross Validation
N-fold Cross Validation
Classification: Probabilistic Generative Model
P(C1∣x)=P(x∣C1)P(C1)+P(x∣C2)P(C2)P(x∣C1)P(C1)
Generative Model P(x)=P(x∣C1)P(C1)+P(x∣C2)P(C2)
Gaussian Distribution
fμ,Σ(x)=(2π)D/21∣Σ∣1/21exp{−21(x−μ)TΣ−1(x−μ)}
P(x∣cn)=fμn,Σn(x)
Input: vector x, output: probability of sampling x
The shape of the function determines by mean μ and convariance matrix Σ
Maximum Likelihood
We have n examples: x1,x2,⋯,xn, feature m 个
L(μ,Σ)=n∏fμ,Σ(xn)
μ∗,Σ∗=argμ,ΣmaxL(μ,Σ)
μ∗=n1n∑xn (average) 会得到一个m×1的矩阵Σ∗=n1n∑(xn−μ∗)(xn−μ∗)T m×m的矩阵
Modifying Model
假设两个classification共享 the same convariance matrix Σ
Class 1: 79个, Class 2: 61个
Find μ1,μ2,Σ maximizing the likelihood L(μ1,μ2,Σ)
L(μ1,μ2,Σ)=n1∏fμ1,Σ(n1)×n2∏fμ2,Σ(n2)
μ1 and μ2 is the same Σ=14079Σ1+14061Σ2
变成linear model
Probability Distribution

Posterior Probability
P(C1∣x)=P(x∣C1)P(C1)+P(x∣C2)P(C2)P(x∣C1)P(C1)=1+P(x∣C1)P(C1)P(x∣C2)P(C2)1=1+exp(−z)1=σ(z)z=lnP(x∣C2)P(C2)P(x∣C1)P(C1)
σ(z): sigmoid function
经过运算,
z=ln∣Σ1∣1/2∣Σ2∣1/2−21xT(Σ1)−1x+(μ1)T(Σ1)−1x−21(μ1)T(Σ1)−1μ1+21xT(Σ2)−1x−(μ2)T(Σ2)−1x+21(μ2)T(Σ2)−1μ2+lnN2N1
Σ1=Σ2=Σ
z=(μ1−μ2)TΣ−1x−21(μ1)TΣ−1μ1+21(μ2)TΣ−1μ2+lnN2N1=wTx+b
P(C1∣x)=σ(w⋅x+b)
Logistic Regression
fw,b(x)=σ(i∑wixi+b)
Training data: (xn,y^n)
y^n: 1 for class 1, 0 for class 2
L(f)=n∑C(f(xn),y^n)
Cross entropy:
C(f(xn),y^n)=−[y^nlnf(xn)+(1−y^n)ln(1−f(xn))]
partial it,
wi←wi−ηn∑−(y^n−fw,b(xn))xin
Just the same as linear regression
Discriminative v.s Generative
discriminative: logistic
generative: naive
结果是不一样的
discriminative 效果比 generative 好
Benefit of generative model
在数据量比较小的时候,generative会赢
noisy, gen wins
priors and class-dependent probabilities can be estimated from different sources.
Multi-class Classification
C1:w1⋅x+b1z1=w1⋅x+b1C2:w2⋅x+b2z2=w2⋅x+b2C3:w3⋅x+b3z3=w3⋅x+b3x=y
y1=ez1/j=1∑3ezjy2=ez2/j=1∑3ezjy3=ez3/j=1∑3ezjSoftmax
yi=P(Ci∣x)
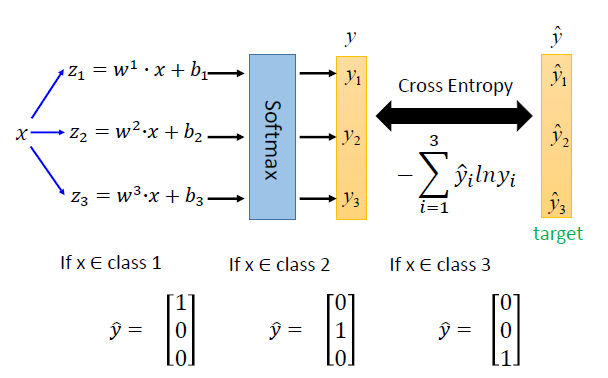
上图有误:
cross entropy: −i=1∑3yi^lnyi
Limitation of Logistic Regression
非线性
Brief Introduction of Deep Learning
deep = Many hidden layers
Matrix Operation
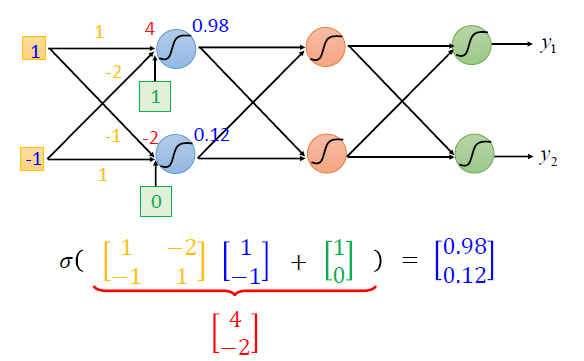
σ(wLaL−1+bL)
y=f(x)=σ(wL⋯σ(w2σ(w1x+b1)+b2)+⋯+bL)
Backprogation
To compute the gradients effiently, we use backpropagation